
Certificate of Analysis verifies that products meet specified standards before reaching the customer or the market. However, a persistent challenge across organizations is the lack of standardization in CoA formats. These documents vary widely by supplier, product, geography, and even over time—posing major hurdles for automation and compliance.
This is where Machine Learning (ML) comes into play. Unlike rule-based systems that break under inconsistency, ML adapts and evolves—making it ideal for managing CoA variability at scale.
The Challenge: CoA Format Chaos
A single enterprise might receive CoAs from hundreds of suppliers, each using different formats, languages, data placements, and terminologies. One supplier may list “Moisture %,” another might call it “Water Content,” while a third might abbreviate it as “H2O.” Manual processing is slow, error-prone, and unsustainable—especially when compliance and customer satisfaction are on the line.
How ML Tackles the Problem
1. Smart Pattern Recognition
ML models can be trained on large volumes of CoA documents to recognize patterns, even when layouts differ. Whether the data is embedded in a table, embedded in paragraphs, or scattered across scanned PDFs, ML can identify and map it to structured fields.
2. Natural Language Understanding (NLU)
Using advanced Natural Language Processing (NLP), ML models understand different ways the same parameter can be represented. They learn from context—so “Total Impurities” and “Combined Impurities” can be treated as the same parameter based on historical training data.
3. Layout Agnosticism
Traditional data extraction relies on fixed templates. ML-driven IDP (Intelligent Document Processing) engines go beyond that by learning from layout variation. They adapt to new document structures, eliminating the need for reconfiguring templates every time a supplier updates their format.
4. Entity Extraction and Label Mapping
ML models can tag and extract relevant entities—like compound names, units, and test values—then match them against a predefined master list. This creates standardized data from highly variable inputs.
5. Continuous Learning
The beauty of ML is that it gets smarter over time. Every manual correction made by a human reviewer can be used to retrain the model, improving its accuracy and adaptability in handling future CoAs.
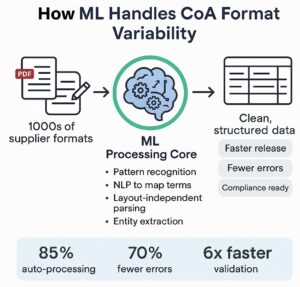
Real-World Example
A global pharmaceutical company receives CoAs from over 1,000 vendors worldwide. Previously, a team of 25 quality assurance personnel spent hours validating each document manually.
After deploying an ML-based CoA automation solution:
Over 85% of documents were processed automatically.
The error rate dropped by 70%.
Validation cycle time reduced from 48 hours to under 6.
All this while seamlessly handling new document formats without any manual reprogramming.
The Payoff: Speed, Accuracy, and Compliance
By embracing ML to manage CoA variability, companies benefit from:
Faster product release cycles
Improved data accuracy
Reduced regulatory risk
Significant operational cost savings
Moreover, ML-driven CoA automation supports audit readiness, as every extracted value can be traced back to its source, maintaining transparency and control.
The variability of Certificate of Analysis formats is a real barrier to automation—but not an insurmountable one. Machine Learning offers a flexible, scalable, and intelligent approach to overcoming this challenge. For any enterprise looking to modernize its quality assurance workflows and stay compliant in a dynamic regulatory environment, ML isn’t just an option—it’s a necessity.


