Blogs, News & Articles

Top 20 FAQs About MTR and COA Automation Answered
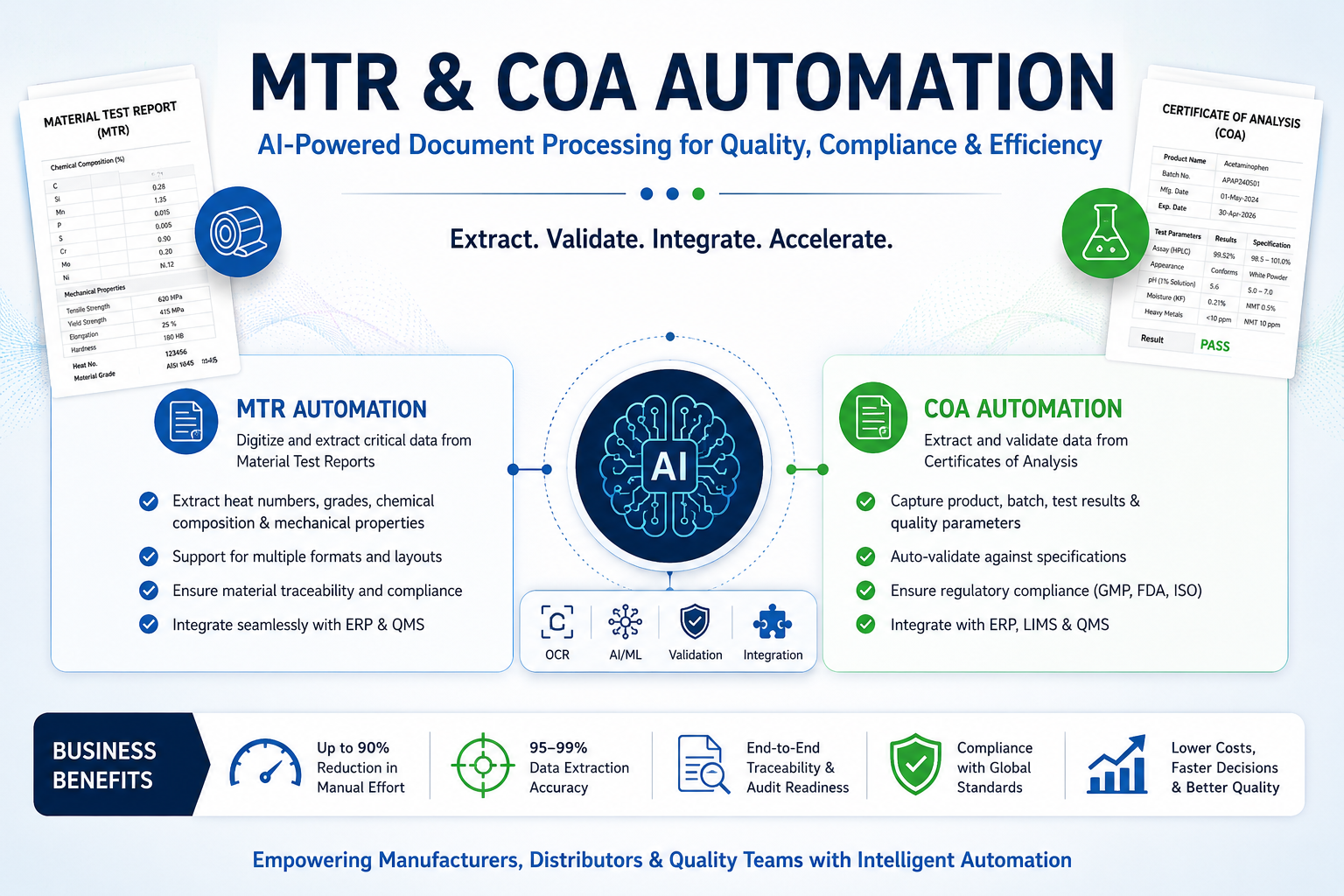
Material Test Reports (MTRs) and Certificates of Analysis (COAs) are critical documents for ensuring quality, compliance, and traceability across manufacturing, metals, chemicals, pharmaceuticals, and food industries.
The Challenges of Intelligent Data Extraction—and How AI Is Transforming the Process
Organizations today generate and receive vast amounts of information in the form of invoices, contracts, purchase orders, forms, reports, emails, certificates, medical records, and countless other documents. While digital transformation initiatives have accelerated over the past decade, extracting meaningful information from these documents remains a significant challenge.
This is where Intelligent Data Extraction (IDE) has emerged as a critical capability. By automatically identifying, extracting, and structuring information from documents, organizations can reduce manual effort, improve accuracy, and accelerate business processes.
However, intelligent data extraction is far from simple. Despite advances in OCR (Optical Character Recognition) and automation technologies, organizations continue to face obstacles that limit extraction accuracy and scalability.
Fortunately, recent developments in Artificial Intelligence (AI), machine learning, and large language models (LLMs) are helping address many of these longstanding challenges.
What Is Intelligent Data Extraction?
Intelligent Data Extraction refers to the process of automatically capturing information from structured, semi-structured, and unstructured documents and converting it into usable, machine-readable data.
Common applications include:
- Invoice processing
- Insurance claims handling
- Contract analysis
- Healthcare records management
- Compliance documentation
- Supplier onboarding
- Financial reporting
- Quality and manufacturing documentation
The ultimate goal is to eliminate manual data entry and enable faster, more accurate decision-making.
Why Data Extraction Remains Challenging
Although document digitization has become widespread, extracting data reliably is often more difficult than organizations expect.
1. Document Variability
One of the biggest challenges is the lack of standardization.
A single business process may involve hundreds or thousands of document formats. Suppliers, customers, partners, and regulators often use their own templates, layouts, and terminology.
For example:
- Banks receive financial statements from different institutions.
- Manufacturers receive quality certificates from multiple suppliers.
- Healthcare providers process records from numerous clinics and laboratories.
Traditional extraction systems often struggle when document formats change frequently.
2. Poor Document Quality
Documents frequently arrive in less-than-ideal conditions:
- Scanned copies
- Photographs taken with mobile phones
- Faxed documents
- Low-resolution PDFs
- Handwritten forms
Even advanced OCR systems can struggle with blurry text, skewed images, stains, signatures, and overlapping content.
A common example is insurance claims processing, where adjusters often submit photographs and scanned forms with varying quality levels.
3. Unstructured Data
Not all business information appears in neat tables or forms.
Critical information may be embedded within:
- Emails
- Legal contracts
- Technical reports
- Medical notes
- Audit findings
Unlike structured documents, unstructured content requires systems to understand context and language rather than simply recognize text.
4. Multiple Languages and Terminologies
Global organizations frequently process documents in multiple languages.
Challenges include:
- Language-specific formats
- Regional date conventions
- Industry jargon
- Local abbreviations
- Specialized technical terminology
For example, pharmaceutical companies often receive regulatory documents from suppliers operating across different countries and regulatory environments.
5. Complex Tables and Nested Data
Many documents contain:
- Multi-row tables
- Merged cells
- Hierarchical structures
- Cross-referenced information
Traditional OCR systems may recognize text accurately but fail to preserve relationships between data elements.
Financial statements and laboratory reports are common examples where table interpretation becomes essential.
6. Compliance and Accuracy Requirements
In regulated industries, even small extraction errors can have significant consequences.
Industries such as:
- Healthcare
- Financial services
- Pharmaceuticals
- Aerospace
- Manufacturing
often require near-perfect accuracy because extracted data may be used for audits, compliance reporting, safety decisions, or regulatory submissions.
As a result, organizations cannot rely solely on automation without validation mechanisms.
7. Scalability Challenges
Many organizations begin with pilot automation projects only to discover that scaling across departments introduces new complexities.
As document volumes grow:
- New document types appear
- Business rules evolve
- Supplier formats change
- Regulatory requirements expand
Maintaining extraction models manually becomes increasingly difficult.
How AI Is Transforming Intelligent Data Extraction
Recent advances in AI are helping organizations overcome many of these challenges.
AI Goes Beyond Traditional OCR
Traditional OCR answers one question:
"What characters are on the page?"
AI answers a more important question:
"What does this information mean?"
This shift enables systems to understand context, relationships, and intent rather than simply converting images into text.
1. Document Understanding
Modern AI systems can identify:
- Document types
- Key sections
- Headings
- Tables
- Signatures
- Important fields
Instead of relying on fixed templates, AI learns patterns across thousands of document variations.
For example, an AI model can recognize an invoice even when suppliers use completely different layouts.
2. Natural Language Processing (NLP)
Natural Language Processing enables systems to understand human language.
This allows extraction platforms to:
- Identify entities
- Detect relationships
- Interpret context
- Summarize content
In legal contract analysis, AI can identify renewal clauses, payment terms, obligations, and risks without requiring manually defined extraction rules.
3. Machine Learning Adaptation
Traditional extraction systems often require manual configuration whenever document formats change.
Machine learning models improve over time by learning from:
- User corrections
- Historical documents
- New document variations
This adaptability significantly reduces maintenance requirements.
4. Table and Layout Intelligence
Modern AI models can understand document structure.
They can:
- Reconstruct tables
- Preserve row-column relationships
- Identify nested information
- Extract multi-page datasets
This capability is particularly valuable in financial services, healthcare diagnostics, and manufacturing quality reporting.
5. Multilingual Processing
Advanced AI systems increasingly support multilingual extraction.
Organizations can process documents across languages while maintaining consistent workflows.
This reduces the need for language-specific extraction systems and supports global business operations.
6. Large Language Models (LLMs)
Large Language Models represent one of the most significant advances in document intelligence.
LLMs can:
- Interpret complex instructions
- Extract context-specific information
- Generate summaries
- Answer questions about documents
- Handle ambiguous content
For example, rather than extracting every field individually, an LLM can answer:
"What are the payment obligations in this contract?"
or
"What compliance risks are mentioned in this report?"
This creates entirely new possibilities for document-driven workflows.
Industry Examples
Financial Services
Banks and lenders use AI-powered extraction to process:
- Loan applications
- Tax documents
- Financial statements
- Customer onboarding forms
This accelerates decision-making while reducing manual review workloads.
Healthcare
Healthcare providers leverage AI to extract information from:
- Patient records
- Laboratory reports
- Insurance claims
- Referral documents
The result is improved administrative efficiency and faster access to clinical information.
Manufacturing
Manufacturers use intelligent extraction to process:
- Supplier documentation
- Inspection reports
- Quality records
- Compliance certificates
Automated extraction helps improve traceability and reduce manual data entry.
Legal Services
Law firms increasingly rely on AI for:
- Contract review
- Due diligence
- Discovery processes
- Regulatory analysis
AI enables legal teams to review large document collections more efficiently.
The Human-in-the-Loop Future
Despite significant advances, fully autonomous extraction remains unrealistic for many high-stakes applications.
The most effective systems combine:
- AI-driven automation
- Business rule validation
- Human review for exceptions
This "human-in-the-loop" approach balances efficiency with accuracy and compliance.
Rather than replacing human expertise, AI augments it by handling repetitive tasks while allowing professionals to focus on judgment-based decisions.
Looking Ahead
Intelligent data extraction is evolving from simple OCR toward comprehensive document understanding.
As AI technologies continue to advance, organizations will increasingly move beyond extracting data to understanding, validating, and acting on information automatically.
The future of intelligent data extraction is not simply about reading documents faster. It is about transforming documents into actionable knowledge that supports better decisions, stronger compliance, and more efficient operations.
Organizations that successfully combine AI, machine learning, and human expertise will be best positioned to unlock the full value of their information assets in the years ahead.
Sources:

SAP, Oracle, Microsoft Dynamics, or NetSuite: How to Automate MTR and COA Data Across Any ERP
ERP Systems Are Only as Good as the Data They Receive
Manufacturers, distributors, pharmaceutical companies, metal service centers, and construction firms invest heavily in ERP platforms such as SAP, Oracle, Microsoft Dynamics, and NetSuite to streamline operations, improve visibility, and support decision-making.
Yet many organizations continue to struggle with one critical process: capturing and managing data from quality documents such as Mill Test Reports (MTRs) and Certificates of Analysis (COAs).
The problem is not the ERP itself. The challenge lies in how quality data enters the ERP.
Most MTRs and COAs arrive as PDFs, scanned documents, emails, spreadsheets, or supplier-generated reports in different formats. Before the data can be used for quality control, compliance, inventory management, or traceability, someone must manually extract and enter it into the ERP system.
This manual process creates delays, errors, and compliance risks that can undermine the value of even the most sophisticated ERP deployment.
Why ERP Systems Struggle with MTR and COA Documents
ERP platforms excel at processing structured data. They can efficiently manage purchase orders, inventory transactions, invoices, and production records.
However, MTRs and COAs are fundamentally different.
Every supplier uses unique templates, layouts, terminologies, and reporting standards. A steel manufacturer may receive hundreds of MTR formats from different mills, while a pharmaceutical company may process COAs from multiple ingredient suppliers worldwide.
Common challenges include:
- Inconsistent document formats
- Multiple units of measurement
- Handwritten annotations
- Missing or incomplete data
- Complex test result tables
- Supplier-specific terminology
- Multi-page certificates
As a result, organizations often rely on manual data entry teams to bridge the gap between supplier documents and ERP systems.
The Hidden Cost of Manual Processing
A typical quality document workflow involves:
- Receiving the certificate
- Downloading or scanning the file
- Reviewing data manually
- Entering information into the ERP
- Validating entries
- Filing documents for future audits
While the process appears straightforward, it creates several operational challenges:
Increased Risk of Errors
Even small transcription mistakes can impact quality records, inventory tracking, and compliance reporting.
Delayed Material Release
Production teams often wait for certificate verification before materials can be approved for use.
Higher Labor Costs
Quality and procurement teams spend valuable time performing repetitive administrative tasks.
Audit Challenges
Locating supporting certificates during audits can become difficult when documents are stored separately from ERP records.
Incomplete Traceability
Without accurate document integration, organizations struggle to establish a complete material genealogy.
What MTR and COA Automation Looks Like
Modern Document AI solutions automate the entire process from document receipt to ERP update.
The workflow typically includes:
Step 1: Document Capture
Certificates are automatically collected from:
- Email inboxes
- Supplier portals
- Shared folders
- Scanned uploads
- ERP attachments
Step 2: Intelligent Data Extraction
AI-powered systems identify and extract:
- Heat numbers
- Batch numbers
- Material grades
- Chemical compositions
- Mechanical properties
- Test results
- Supplier information
- Manufacturing dates
- Expiry dates
Unlike traditional OCR, modern Document AI understands document context and can process multiple supplier formats without template creation.
Step 3: Validation and Business Rules
Extracted data is validated against:
- ERP master records
- Material specifications
- Customer requirements
- Regulatory standards
Exceptions are automatically flagged for review.
Step 4: ERP Integration
Validated data is pushed directly into the ERP system using APIs, middleware, or native connectors.
Step 5: Searchable Digital Repository
Certificates remain linked to ERP transactions, creating a complete audit trail.
--------------------------------------------------------------------------------------------------------
Automating MTR and COA Data Across Major ERP Platforms
SAP
SAP environments often support highly regulated industries where traceability is critical.
Automation solutions can:
- Populate SAP quality management modules
- Update batch records automatically
- Link certificates to material masters
- Support supplier quality workflows
- Improve audit readiness
Organizations using SAP frequently seek automation to eliminate manual quality data entry while maintaining strict validation controls.
Oracle
Oracle ERP users often manage complex global supply chains.
Automated certificate processing can:
- Standardize supplier data ingestion
- Improve supplier quality management
- Enhance procurement visibility
- Reduce compliance risks
- Accelerate material approvals
By automating document extraction, organizations gain faster access to quality data without increasing administrative workload.
Microsoft Dynamics
Dynamics users often prioritize operational efficiency and rapid process improvements.
Automation helps:
- Reduce manual data entry
- Improve inventory accuracy
- Strengthen quality management
- Support manufacturing workflows
- Enhance customer traceability reporting
For growing manufacturers, automation provides a scalable method for handling increasing document volumes.
NetSuite
NetSuite is commonly used by fast-growing organizations that require cloud-based operations.
Automated MTR and COA processing can:
- Streamline receiving operations
- Accelerate quality inspections
- Improve inventory visibility
- Support regulatory compliance
- Reduce dependence on manual processes
As transaction volumes grow, automation helps maintain efficiency without expanding administrative teams.
----------------------------------------------------------------------------------------------------------------------
The ERP Integration Challenge
Many organizations assume ERP integration requires extensive customization projects.
In reality, modern automation platforms are designed to integrate with virtually any ERP architecture.
Successful integrations typically support:
- REST APIs
- Web services
- Database connectors
- Middleware platforms
- Flat-file imports
- EDI environments
- Cloud and on-premise deployments
This flexibility enables organizations to automate certificate processing without disrupting existing ERP investments.
How Star Software Simplifies MTR and COA Automation
The platform combines:
- AI-powered document understanding
- Advanced OCR capabilities
- Intelligent validation workflows
- ERP integration frameworks
- Material traceability tools
- Searchable certificate repositories
Instead of forcing organizations to redesign their ERP systems, Star Software acts as the intelligent layer between supplier documents and enterprise applications.
This approach enables businesses to:
- Reduce manual processing effort
- Improve data accuracy
- Accelerate material approvals
- Strengthen compliance readiness
- Enhance supplier quality management
- Achieve end-to-end material traceability
Whether an organization uses SAP, Oracle, Microsoft Dynamics, NetSuite, or a custom ERP environment, the objective remains the same: convert quality documents into trusted, structured data that drives operational decisions.
The Future of ERP Is Document Intelligence
As manufacturers continue their digital transformation journeys, the value of ERP systems will increasingly depend on the quality and accessibility of the data they contain.
MTRs and COAs represent a rich source of quality and compliance information, but only when that information can be captured accurately and efficiently.
Organizations that automate certificate processing gain more than labor savings. They create stronger traceability, faster decision-making, improved compliance, and greater confidence in their operational data.
The future is not about replacing ERP systems. It is about making them smarter through intelligent document automation.
Sources:
https://www.sap.com/products/erp.html
https://www.gartner.com/en/information-technology
https://www.mckinsey.com/capabilities/tech-and-ai/our-insights
What is Document AI and Why is Every Enterprise Talking About It?
Organizations generate and process millions of documents every day—contracts, invoices, purchase orders, KYC documents, material test reports (MTRs), certificates of analysis (COAs), inspection reports, shipping documents, compliance records, and more. Yet a significant portion of this information remains trapped inside PDFs, scanned images, emails, and paper-based workflows.
This challenge has created one of the fastest-growing technology categories in enterprise software: Document AI.
According to MarketsandMarkets, the global Document AI market is expected to grow from USD 14.66 billion in 2025 to USD 27.62 billion by 2030, representing a CAGR of 13.5%. The growth is being driven by increasing demand for intelligent automation, AI-powered data extraction, and industry-specific document processing solutions.
But what exactly is Document AI, and why are enterprises investing heavily in it?
Understanding Document AI
Document AI refers to the use of Artificial Intelligence technologies—including Optical Character Recognition (OCR), Machine Learning (ML), Natural Language Processing (NLP), Computer Vision, and Generative AI—to automatically read, understand, classify, extract, validate, and process information from documents.
Traditional OCR can identify text from an image or scanned document. Document AI goes several steps further.
Instead of simply reading text, it understands:
- Document structure
- Tables and forms
- Context and relationships
- Signatures and stamps
- Handwritten content
- Industry-specific terminology
- Business rules and workflows
For example, when processing a Mill Test Report, traditional OCR may extract chemical composition values. Document AI can identify which values belong to which heat number, validate them against specifications, detect missing fields, and automatically route the document for approval.
In short, Document AI transforms documents from static files into actionable business data.
Why Traditional OCR Is No Longer Enough
For decades, businesses relied on OCR to digitize documents. While useful, OCR has several limitations:
- Difficulty handling complex layouts
- Limited understanding of context
- Poor performance on tables
- High manual verification requirements
- Challenges with handwritten data
- Inability to make business decisions
Modern enterprises deal with highly variable and unstructured documents. A supplier invoice may look different from every other invoice. A material certificate may contain tables, graphs, stamps, and handwritten annotations.
Document AI addresses these challenges by combining multiple AI technologies to understand documents much like a human reviewer would.
The Business Problem Driving Adoption
One of the biggest drivers behind Document AI adoption is the explosion of unstructured data.
According to Gartner estimates cited by CIO, 80% to 90% of newly generated enterprise data is unstructured, and this data is growing three times faster than structured data.
Unfortunately, most business-critical information exists within this unstructured content.
Organizations often spend thousands of employee hours on:
- Manual data entry
- Document verification
- Compliance checks
- Vendor onboarding
- Quality inspections
- Audit preparation
- Customer onboarding
These activities increase costs, create bottlenecks, and introduce human errors.
Document AI automates these processes while improving accuracy and speed.
How Document AI Works
A typical Document AI workflow consists of several stages:
1. Document Capture
Documents enter the system through:
- Scanners
- Email attachments
- PDFs
- Mobile uploads
- Enterprise systems
2. Classification
The AI identifies document types such as:
- Invoices
- Purchase orders
- KYC forms
- MTRs
- COAs
- Contracts
3. Data Extraction
Relevant information is automatically extracted.
Examples include:
- Customer details
- Invoice amounts
- Material grades
- Chemical compositions
- Inspection results
- Compliance fields
4. Validation
Business rules validate extracted data against predefined standards.
5. Workflow Automation
The information is routed into ERP, CRM, Quality Management, Procurement, or Compliance systems.
6. Continuous Learning
Modern systems improve accuracy over time through human feedback and machine learning.
Why Every Enterprise Is Talking About Document AI
1. Massive Productivity Gains
Intelligent Document Processing (IDP), a key component of Document AI, significantly reduces manual effort.
Research and industry case studies show that organizations can automate large portions of document-heavy processes while improving accuracy and consistency.
In one enterprise case study combining Generative AI and IDP, organizations achieved over 80% reduction in processing time while reducing errors and improving compliance.
2. Better Compliance and Risk Management
Industries such as banking, healthcare, manufacturing, pharmaceuticals, and construction face strict compliance requirements.
Document AI helps organizations:
- Verify documentation automatically
- Detect anomalies
- Maintain audit trails
- Reduce compliance risks
This is especially valuable for KYC verification, supplier qualification, quality assurance, and regulatory reporting.
3. Faster Decision-Making
Instead of waiting hours or days for document reviews, decision-makers receive structured information in real time.
For example:
- Loan approvals become faster
- Vendor onboarding accelerates
- Material inspections are completed sooner
- Accounts payable cycles shorten
4. Improved Data Quality
Manual data entry introduces errors.
Document AI reduces these risks by standardizing extraction and validation processes, resulting in cleaner and more reliable business data.
5. Enterprise AI Readiness
Many organizations are now deploying Generative AI and AI Agents.
However, AI systems are only as good as the data they access.
Document AI serves as the foundation by converting unstructured documents into structured, searchable, and trustworthy enterprise knowledge.
The Rise of RAG-Powered Document AI
One of the most important trends in 2026 is the emergence of Retrieval-Augmented Generation (RAG) within Document AI.
Traditional Generative AI can sometimes produce inaccurate or fabricated responses.
RAG solves this problem by allowing AI systems to retrieve information from trusted enterprise documents before generating answers.
MarketsandMarkets identifies RAG-enabled Document AI as a major growth driver because it enables:
- More accurate summarization
- Context-aware reporting
- Compliance-friendly AI outputs
- Better enterprise search
- Reduced hallucinations
This capability is particularly important in regulated industries where accuracy is critical.
Industry Applications of Document AI
Manufacturing
Document AI helps automate:
- Mill Test Reports
- Certificates of Analysis
- Quality inspection reports
- Supplier documentation
Banking and Financial Services
Applications include:
- KYC verification
- Loan processing
- Customer onboarding
- Compliance reporting
Healthcare
Organizations use Document AI for:
- Medical records
- Insurance claims
- Regulatory documentation
Construction and Infrastructure
Key use cases include:
- Material traceability
- Inspection reports
- Compliance certificates
- Contractor documentation
Accounts Payable
Document AI automates:
- Invoice processing
- Purchase order matching
- Vendor onboarding
- Payment approvals
What the Future Looks Like
The next generation of Document AI will move beyond extraction toward intelligence and decision support.
Emerging capabilities include:
- Predictive quality analysis
- AI agents that process documents autonomously
- Industry-specific AI models
- Real-time compliance monitoring
- Multimodal document understanding
- Intelligent workflow orchestration
Rather than simply digitizing documents, enterprises will use Document AI to generate insights, identify risks, and automate decisions.
Final Thoughts
Document AI is no longer just an efficiency tool. It has become a strategic capability for enterprises seeking to improve productivity, reduce risk, strengthen compliance, and unlock value from unstructured information.
As organizations continue their AI transformation journeys, the ability to understand and act on document-based data will become a competitive differentiator.
Whether it is processing invoices, verifying KYC documents, analyzing Material Test Reports, or managing compliance records, Document AI is helping enterprises turn documents into actionable intelligence.
The question is no longer whether organizations should adopt Document AI. The question is how quickly they can implement it before competitors gain the advantage.
Sources:
- MarketsandMarkets – Document AI Market Forecast (2025–2030): Global market projected to grow from USD 14.66B to USD 27.62B at 13.5% CAGR.
- CIO.com - IDP on Content Intensive Processes.
- Gartner Reviews – Definition and capabilities of Document
- Economic Times – Growing importance of Intelligent Document Processing (IDP) in enterprises.
- Cornell University - Academic Research on Document AI and Intelligent Document Processing.

Why Infrastructure Projects Need End-to-End Material Traceability
Infrastructure projects are built to last decades. Whether it is a bridge, highway, airport, railway network, power plant, or commercial complex, the quality of materials used during construction directly impacts safety, durability, compliance, and long-term performance.
Yet many infrastructure projects continue to struggle with fragmented documentation, manual verification processes, and limited visibility into the origin and quality of construction materials. As projects become larger and regulatory requirements become more stringent, end-to-end material traceability is no longer a nice-to-have capability—it is becoming a business necessity.
The Growing Importance of Material Traceability
Material traceability refers to the ability to track a material throughout its lifecycle—from manufacturing and testing to procurement, delivery, installation, and maintenance.
For construction and infrastructure projects, traceability ensures that every critical material, particularly structural steel, pipes, fasteners, concrete reinforcements, and fabricated components, can be linked back to its corresponding Mill Test Report (MTR) or Certificate of Analysis (COA).
This creates a verifiable chain of quality assurance that can be accessed whenever required.
Without traceability, project teams often face significant challenges when verifying compliance, investigating failures, conducting audits, or managing supplier performance.
The Risks of Poor Material Traceability
Quality and Safety Concerns
Infrastructure assets are expected to withstand heavy loads, harsh environmental conditions, and years of continuous use. If substandard or non-compliant materials enter the supply chain, the consequences can be severe.
Inadequate traceability makes it difficult to identify:
- Material substitutions
- Specification deviations
- Supplier quality issues
- Non-compliant batches
- Manufacturing defects
When material records cannot be verified quickly, project owners face increased safety and operational risks.
Project Delays
Construction projects often involve thousands of material certifications arriving from multiple suppliers.
Manual verification of MTRs and COAs can create bottlenecks during:
- Material inspections
- Site approvals
- Vendor onboarding
- Quality audits
- Regulatory reviews
Missing or incorrectly linked documentation can delay project milestones and increase costs.
Compliance Challenges
Government agencies, EPC contractors, and project owners are placing greater emphasis on documentation and traceability requirements.
Infrastructure projects must often demonstrate compliance with:
- ASTM standards
- ASME specifications
- ISO requirements
- Project-specific quality standards
- Regulatory mandates
Failure to produce supporting material certifications can result in project disputes, rework, penalties, or rejected inspections.
Why End-to-End Traceability Matters
End-to-end traceability provides a complete digital record of every material used within a project.
This allows stakeholders to answer critical questions such as:
- Which supplier provided the material?
- Which manufacturing batch did it originate from?
- Was the material tested according to specification?
- Which MTR supports the material?
- Where was the material installed?
- Has the material passed all quality checks?
The ability to access this information instantly improves decision-making and strengthens quality control processes.
The Role of MTR and COA Automation
One of the biggest barriers to achieving traceability is the manual processing of material certifications.
Large infrastructure projects may receive thousands of MTRs and COAs from multiple vendors. Reviewing, validating, and storing these documents manually consumes significant time and resources.
This is where automation is transforming infrastructure quality management.
AI-powered document processing solutions can automatically:
- Extract data from MTRs and COAs
- Validate material specifications
- Match certifications with purchase orders
- Identify discrepancies
- Flag compliance risks
- Create searchable digital records
Instead of spending days reviewing documents, quality teams can verify material compliance within minutes.
How Star Software Enables Material Traceability
Star Software's AI-powered MTR and COA automation platform helps infrastructure companies build a digital foundation for end-to-end material traceability.
The solution automatically captures critical data from material certifications and converts it into structured, searchable information.
Organizations can:
- Digitize material certifications at scale
- Improve supplier compliance monitoring
- Accelerate quality inspections
- Reduce manual verification efforts
- Maintain complete audit trails
- Improve project visibility
By transforming static documents into actionable data, Star Software helps project teams gain real-time insight into material quality and compliance.
Beyond Compliance: Creating Strategic Value
Material traceability delivers benefits that extend far beyond regulatory requirements.
When organizations maintain accurate traceability records, they gain access to valuable insights related to:
Supplier Performance
Analyze quality trends across suppliers and identify recurring compliance issues.
Risk Management
Detect potential material quality concerns before they impact project timelines.
Faster Audits
Provide instant access to supporting documentation during inspections and regulatory reviews.
Lifecycle Management
Maintain accurate records that support future maintenance, repairs, and asset management.
Data-Driven Decisions
Leverage material quality data to improve procurement and project planning strategies.
The Future of Infrastructure Quality Management
As infrastructure projects become increasingly complex, digital traceability will become a standard requirement rather than a competitive advantage.
Project owners, EPC firms, and construction companies that continue relying on paper-based documentation and manual verification processes risk falling behind in an environment where speed, compliance, and accountability are critical.
End-to-end material traceability provides the visibility needed to ensure quality, reduce risk, accelerate project delivery, and improve long-term asset performance.
By combining AI-powered MTR and COA automation with intelligent data management, Star Software is helping infrastructure organizations build stronger, safer, and more compliant projects—one material certification at a time.